322. 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
示例 2:
输入:coins = [2], amount = 3
输出:-1
示例 3:
输入:coins = [1], amount = 0
输出:0

class Solution {
public int coinChange(int[] coins, int amount) {
int max = Integer.MAX_VALUE;
int[] dp = new int[amount + 1];
//初始化dp数组为最大值
for (int j = 0; j < dp.length; j++) {
dp[j] = max;
}
//当金额为0时需要的硬币数目为0
dp[0] = 0;
for (int i = 0; i < coins.length; i++) {
//正序遍历:完全背包每个硬币可以选择多次
for (int j = coins[i]; j <= amount; j++) {
//只有dp[j-coins[i]]不是初始最大值时,该位才有选择的必要
if (dp[j - coins[i]] != max) {
//选择硬币数目最小的情况
dp[j] = Math.min(dp[j], dp[j - coins[i]] + 1);
}
}
}
return dp[amount] == max ? -1 : dp[amount];
}
}
这段Java代码实现了一个经典的动态规划问题——“完全背包问题”的一个应用场景:给定不同面额的硬币coins和一个总金额amount,计算最少需要多少个硬币凑出这个金额,如果不可能凑出则返回-1。这里是使用完全背包的思路,即每种硬币可以无限使用。
代码解析:
-
初始化:首先,定义一个
dp数组,长度为amount + 1,并将其所有值初始化为Integer.MAX_VALUE,表示在没有计算之前,达到每个金额所需的最小硬币数为正无穷大。例外的是,dp[0]初始化为0,因为当金额为0时,不需要任何硬币。 -
双重循环:
- 外层循环遍历硬币数组
coins,即遍历每一种硬币面额。 - 内层循环从当前硬币的面额
coins[i]开始遍历到总金额amount。这是因为在遍历到的金额j上,只有当j至少为当前硬币面额时,才有可能使用当前硬币去构成这个金额。
- 外层循环遍历硬币数组
-
状态转移方程:对于内层循环中的每个
j,如果dp[j - coins[i]]不是初始的最大值(即存在一种方式可以构成j - coins[i]的金额),则考虑使用一个面额为coins[i]的硬币,更新dp[j]为dp[j]和dp[j - coins[i]] + 1中的较小值。这里dp[j - coins[i]] + 1表示在构成j - coins[i]的基础上再加一个面额为coins[i]的硬币。 -
返回结果:最后,检查
dp[amount]是否仍为Integer.MAX_VALUE,如果是,则说明没有找到任何组合可以凑成总金额,返回-1;否则返回dp[amount],即最少需要的硬币数。
总结:
这段代码通过动态规划的完全背包方法,有效解决了最少硬币数量问题,时间复杂度为O(coins.length * amount),空间复杂度为O(amount)。
279. 完全平方数
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
示例 2:
输入:n = 13
输出:2
解释:13 = 4 + 9

方法一:
class Solution {
// 版本一,先遍历物品, 再遍历背包
public int numSquares(int n) {
int max = Integer.MAX_VALUE;
int[] dp = new int[n + 1];
//初始化
for (int j = 0; j <= n; j++) {
dp[j] = max;
}
//如果不想要寫for-loop填充數組的話,也可以用JAVA內建的Arrays.fill()函數。
//Arrays.fill(dp, Integer.MAX_VALUE);
//当和为0时,组合的个数为0
dp[0] = 0;
// 遍历物品
for (int i = 1; i * i <= n; i++) {
// 遍历背包
for (int j = i * i; j <= n; j++) {
//if (dp[j - i * i] != max) {
dp[j] = Math.min(dp[j], dp[j - i * i] + 1);
//}
//不需要這個if statement,因爲在完全平方數這一題不會有"湊不成"的狀況發生( 一定可以用"1"來組成任何一個n),故comment掉這個if statement。
}
}
return dp[n];
}
}
这段Java代码是解决完全平方数问题的一个动态规划实现,目标是找出最少数量的完全平方数(例如1, 4, 9, 16…)之和,使其等于给定的正整数n。代码采用了“先遍历物品,再遍历背包”的动态规划策略,这里的“物品”指的是完全平方数,而“背包”则是我们需要达到的目标和n。
代码解析
-
初始化dp数组:首先,创建一个长度为
n+1的数组dp,其中dp[j]表示和为j时所需的最少完全平方数的个数。初始化所有dp[j]为Integer.MAX_VALUE,表示初始时没有找到任何组合。但因为任何正整数都可以由无数个1^2组成,所以实际上不需要初始化为Integer.MAX_VALUE,直接初始化为一个较大的数即可,或明确知道最小组合数为1(当j > 0时)。注释中提到的Arrays.fill(dp, Integer.MAX_VALUE);是一种更简洁的初始化方式,但在这个特定问题上下文里,初始化为极大值然后在特定条件下更新的逻辑是多余的。 -
初始化dp[0]:当和为0时,不需要任何完全平方数,所以
dp[0]设置为0。 -
双重循环:
- 外层循环遍历所有可能的完全平方数(由
1^2到√n的平方),用i表示当前考虑的完全平方数的根。 - 内层循环遍历从当前完全平方数
i*i开始到目标和n的所有可能和j。对于每个j,如果可以通过添加当前完全平方数i*i使得总和不超过n,并且这样的操作能减少之前记录的最少完全平方数的个数,就更新dp[j]的值为dp[j - i * i] + 1。
- 外层循环遍历所有可能的完全平方数(由
-
返回结果:最后返回
dp[n],即和为n时所需的最少完全平方数的个数。
注意
- 代码注释中指出的“不需要这个if statement”,是因为在找完全平方数之和的问题中,任何正整数
n都可以通过至少一个1^2(即至少一个1)来组合得到,所以直接尝试更新dp[j]的值而不需检查之前是否达到过是不可能的状态(即dp[j - i * i] != max的检查没有必要)。
综上,这段代码通过动态规划方法有效地求解了最少完全平方数之和的问题。
方法二:
class Solution {
// 版本二, 先遍历背包, 再遍历物品
public int numSquares(int n) {
int max = Integer.MAX_VALUE;
int[] dp = new int[n + 1];
// 初始化
for (int j = 0; j <= n; j++) {
dp[j] = max;
}
// 当和为0时,组合的个数为0
dp[0] = 0;
// 遍历背包
for (int j = 1; j <= n; j++) {
// 遍历物品
for (int i = 1; i * i <= j; i++) {
dp[j] = Math.min(dp[j], dp[j - i * i] + 1);
}
}
return dp[n];
}
}
这段Java代码是解决“完全平方数”的另一个动态规划实现版本,目标依然是找出最少数量的完全平方数(如1, 4, 9, 16…)之和,使得这个和等于给定的正整数n。与第一个版本的主要区别在于遍历的顺序:这里是“先遍历背包,再遍历物品”。
代码解析
-
初始化:与第一个版本相同,首先创建一个长度为
n+1的数组dp,其中dp[j]表示和为j时所需的最少完全平方数的个数。初始化所有dp[j]为Integer.MAX_VALUE,然后设置dp[0]=0,表示和为0时不需要任何完全平方数。 -
遍历顺序改变:
- 外层循环现在遍历背包容量(从1到
n),用j表示当前考虑的总和。 - 内层循环遍历所有可能的完全平方数(从
1^2到刚好不超过当前总和j的完全平方数),用i表示当前完全平方数的根。这确保了每次内循环都是对一个有效的完全平方数进行操作,不会超出背包容量。
- 外层循环现在遍历背包容量(从1到
-
状态转移:对于每个背包容量
j,遍历所有小于等于它的完全平方数i*i,并尝试将当前完全平方数加入组合中(即从dp[j - i * i]转移而来),然后通过Math.min()函数更新dp[j]为已知的最小组合数。 -
返回结果:最后返回
dp[n],即和为n时,所需最少的完全平方数个数。
优缺点
- 优点:这种“先遍历背包,再遍历物品”的方式直接反映了背包问题的经典解法,逻辑上清晰地表达了对于每个总和
j,尝试用所有可能的完全平方数去填充它,寻找最小组合数。 - 缺点:在这个特定问题上,两种遍历顺序(先物品后背包 vs. 先背包后物品)在逻辑复杂度和效率上并无本质区别,主要取决于个人理解偏好。实际上,由于完全平方数的特殊性(连续的完全平方数之间差距增大),遍历顺序对性能的影响相对较小。
总之,这个版本提供了解决“完全平方数”问题的另一种动态规划实现思路,关键在于遍历顺序的调整,但核心的动态规划思想和状态转移方程保持一致。
139. 单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
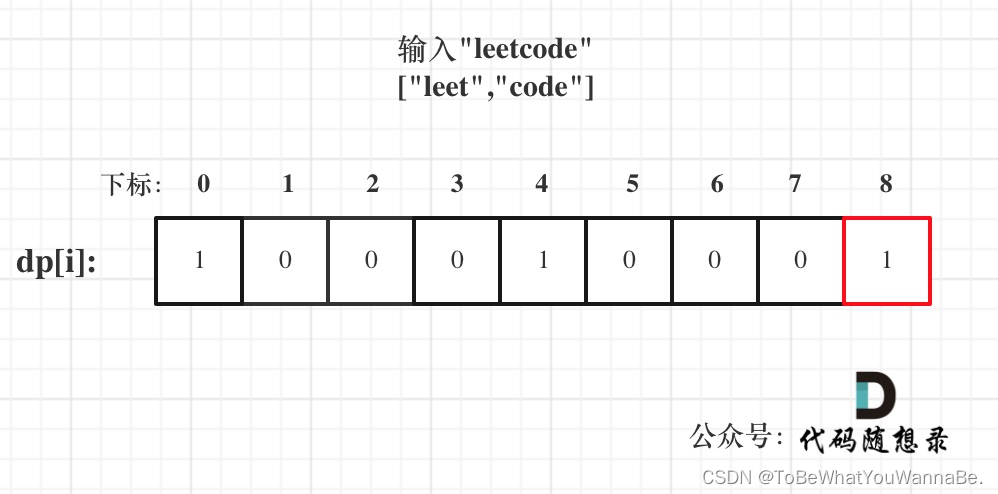
输入: s = “leetcode”, wordDict = [“leet”, “code”]
输出: true
解释: 返回 true 因为 “leetcode” 可以由 “leet” 和 “code” 拼接成。
示例 2:
输入: s = “applepenapple”, wordDict = [“apple”, “pen”]
输出: true
解释: 返回 true 因为 “applepenapple” 可以由 “apple” “pen” “apple” 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = “catsandog”, wordDict = [“cats”, “dog”, “sand”, “and”, “cat”]
输出: false
方法一:
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
HashSet<String> set = new HashSet<>(wordDict);
boolean[] valid = new boolean[s.length() + 1];
valid[0] = true;
for (int i = 1; i <= s.length(); i++) {
for (int j = 0; j < i && !valid[i]; j++) {
if (set.contains(s.substring(j, i)) && valid[j]) {
valid[i] = true;
}
}
}
return valid[s.length()];
}
}
这段Java代码是一个解决方案,用于解决“单词拆分”问题。给定一个字符串s和一个字典wordDict(单词列表),判断字符串s是否可以被空格拆分成一个或多个字典中的单词。这是一个典型的动态规划问题。
代码解析
-
数据结构转换:首先,将
wordDict转换为哈希集合HashSet<String> set,这样可以以O(1)的时间复杂度查询一个字符串是否在字典中。 -
初始化:定义一个布尔型数组
valid,长度为s.length() + 1,其中valid[i]表示字符串s的前i个字符组成的子串是否可以被拆分成字典中的单词。初始化valid[0]为true,因为空字符串是可以“拆分”的。 -
动态规划填充:外层循环从1遍历到
s.length(),代表当前正在检查的子串的结束位置。内层循环从0遍历到当前的结束位置i,这是为了找到所有可能的前缀子串。如果存在某个前缀子串(从索引j到i)在字典集合中,并且这个前缀子串的前一个位置(即j)的子串也是合法的(valid[j]为true),那么将当前位置i标记为合法(valid[i] = true)。这里使用了!valid[i]作为提前终止的条件,一旦找到一个合法的拆分方式就不再继续查找,提高了效率。 -
返回结果:最后返回
valid[s.length()],即整个字符串s是否可以被成功拆分。
示例
假设s = "leetcode",wordDict = ["leet", "code"],该函数将返回true,因为可以将s拆分成"leet"和"code",这两个单词都在字典中。
这段代码通过动态规划有效地解决了单词拆分问题,具有较好的时间和空间效率。
方法二:
// 另一种思路的背包算法
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true;
for (int i = 1; i <= s.length(); i++) {
for (String word : wordDict) {
int len = word.length();
if (i >= len && dp[i - len] && word.equals(s.substring(i - len, i))) {
dp[i] = true;
break;
}
}
}
return dp[s.length()];
}
}
这段代码同样采用动态规划的思路来解决“单词拆分”问题,但实现方式稍有不同,具体解析如下:
算法思路
-
初始化:创建一个布尔型数组
dp,长度为s.length() + 1,其中dp[i]表示字符串s的前i个字符组成的子串是否能被字典中的单词组合覆盖。初始化dp[0] = true,表示空字符串是可以被任何词典中的单词组合覆盖的。 -
双重循环遍历:
- 外层循环从1遍历到
s.length(),用i表示当前考虑的子串的结束位置。 - 内层循环遍历字典
wordDict中的每个单词word。- 计算当前单词的长度
len。 - 判断当前子串的起始位置是否允许截取长度为
len的子串,即i >= len,同时检查前len个字符组成的子串(即s.substring(i - len, i))是否与当前单词相等,并且这个子串的前一个位置的子串是否能被词典中的单词组合覆盖(即dp[i - len]为true)。 - 如果上述条件满足,说明找到了一个匹配的单词,可以将当前位置
i标记为true并跳出内层循环,因为一旦找到一个合法的拆分方式就没有必要继续检查当前i的其他单词了(利用了“一旦满足条件即可结束”的剪枝优化)。
- 计算当前单词的长度
- 外层循环从1遍历到
-
返回结果:最后返回
dp[s.length()],表示整个字符串s是否可以被字典中的单词组合覆盖。
优势与特点
- 剪枝优化:通过在找到符合条件的单词后立即中断内层循环,减少了不必要的循环次数,提高了算法效率。
- 直观易懂:代码直接体现了对每个子串尝试匹配字典中单词的过程,逻辑较为直观。
- 空间效率:此方法仅使用了一个长度等于字符串长度加一的布尔数组,空间复杂度为O(n),其中n为字符串
s的长度,与题目给定的字典大小无关,较为高效。
综上所述,这是一种有效且易于理解的动态规划解法,适用于解决给定字符串是否能被字典中的单词拆分的问题。
方法三:
// 回溯法+记忆化
class Solution {
private Set<String> set;
private int[] memo;
public boolean wordBreak(String s, List<String> wordDict) {
memo = new int[s.length()];
set = new HashSet<>(wordDict);
return backtracking(s, 0);
}
public boolean backtracking(String s, int startIndex) {
// System.out.println(startIndex);
if (startIndex == s.length()) {
return true;
}
if (memo[startIndex] == -1) {
return false;
}
for (int i = startIndex; i < s.length(); i++) {
String sub = s.substring(startIndex, i + 1);
// 拆分出来的单词无法匹配
if (!set.contains(sub)) {
continue;
}
boolean res = backtracking(s, i + 1);
if (res) return true;
}
// 这里是关键,找遍了startIndex~s.length()也没能完全匹配,标记从startIndex开始不能找到
memo[startIndex] = -1;
return false;
}
}
这段代码提供了一个使用回溯法加记忆化的解决方案来解决“单词拆分”问题。给定一个字符串s和一个单词字典wordDict,判断字符串s是否可以被空格拆分成一个或多个字典中的单词。以下是代码的详细解析:
类成员变量
- set: 存储字典
wordDict中的所有单词,使用HashSet以支持快速查找。 - memo: 记忆化数组,用于存储字符串
s的各个起始位置是否能够被拆分成字典中的单词。初始化为整型数组,长度与s相同,初始值默认为0,-1表示从该位置开始的子串不能被拆分。
方法解析
wordBreak 方法
- 初始化
memo数组和set集合。 - 调用
backtracking方法,从字符串的起始位置开始尝试拆分。
backtracking 方法
-
参数:
s: 输入字符串。startIndex: 当前开始拆分的位置索引。
-
目的:
- 递归地尝试从
startIndex开始的子串是否能被拆分成字典中的单词。
- 递归地尝试从
-
逻辑:
- 基础情况:如果
startIndex等于字符串长度,说明已经成功拆分到末尾,返回true。 - 记忆化检查:如果
memo[startIndex]为-1,说明从startIndex开始的子串已经被探索过且不可拆分,直接返回false。 - 遍历:从
startIndex到字符串结尾,逐步尝试截取子串,并检查该子串是否在字典中。- 如果子串在字典中,递归调用
backtracking(s, i + 1),尝试剩余部分能否拆分。 - 如果剩余部分可以被拆分,则当前子串也能被拆分,返回
true。
- 如果子串在字典中,递归调用
- 回溯:如果所有尝试都无法成功拆分,标记
memo[startIndex] = -1,表示从这个位置开始的子串不能被拆分,然后返回false。
- 基础情况:如果
关键点
- 记忆化搜索:通过
memo数组避免重复计算,提高效率。 - 回溯:在尝试失败后记录失败信息,防止同一子问题的重复探索。
这种方法在处理较长字符串和较大字典时,相较于简单的递归或暴力搜索能显著提升效率,但消耗的空间也会相应增加,主要是由于记忆化数组的使用。